
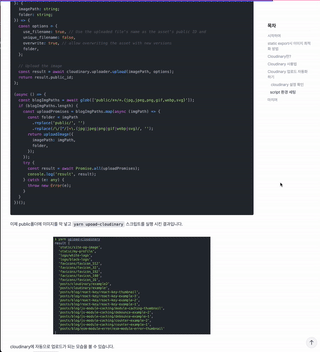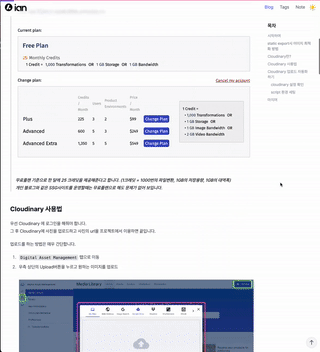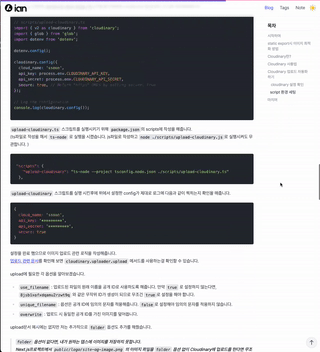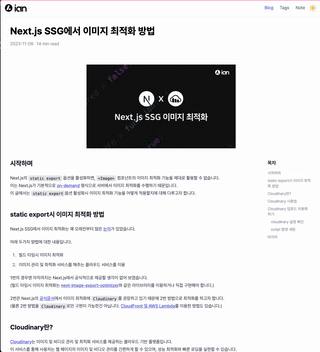
contentlayer에서 rehype와 remark를 활용하여 Markdown 파일을 파싱했을때, 그 결과로 목차(TOC)를 scroll event와 intersection observer로 구현하는 방법을 살펴봅니다. 단, 본 글에서는 contentlayer와 rehype,remark 사용법에 대해서는 다루지 않습니다.
시작하며
개발 블로그를 만들면서 TOC기능을 어떻게 구현했는지 왜 IntersectionObserver를 안쓰게 됐는지 공유하고자 합니다.
TOC란?
책의 TOC를 보면 본문 내용을 간략하게 알거나, 쉽게 찾아 볼 수 있게 해줍니다.
웹 사이트에서의 TOC도 마찬가지입니다.
보통 개발 블로그에서의 TOC는 클릭시 해당 위치로 바로 스크롤을 해주고, 현재 내가 어느 지점의 글을 읽고 있는지 표시를 해줍니다.
어떤 기능을 구현할 것인가?
웹사이트 블로그 글 TOC의 기본이 되는 기능을 구현할 것입니다.(react로 예시코드가 작성되어 있습니다.)
command:gitlens.showGraph
-
현재 읽고 있는 글이 어느 부분인지 파악하기 위해 제목 태그와 매칭되는 목차가 생기면 목차에 하이라이팅 처리
-
TOC를 클릭했을 경우 해당하는 제목 태그로 이동
1. 제목 태그에 id값을 달아주기
TOC를 클릭 했을때 해당하는 제목 태그 위치로 이동을 시켜야 하므로 html heading에 id를 달아줘야 합니다.
rehype-slug라는 라이브러리를 사용하면 다음과 같이 아주 간단하게 제목 태그에 id를 달아줄 수 있습니다.

2. 제목 태그에 id 달아주는 로직 파악하기
목차를 클릭했을 때 글 본문의 heading의 id를 찾아서 이동을 해야하므로 rehype-slug가 id를 어떤식으로 생성을 하는지 알아야합니다.
rehype-slug 가 id를 생성하는 방법을 대강 비스무리하게 구현을 하면 목차와 본문heading의 id가 정확히 매칭이 되지 않을수도 있으므로 rehype-slug 라이브러리 코드를 살펴봅시다.
import GithubSlugger from 'github-slugger'
import {headingRank} from 'hast-util-heading-rank'
import {toString} from 'hast-util-to-string'
import {visit} from 'unist-util-visit'
/** @type {Options} */
const emptyOptions = {}
const slugs = new GithubSlugger()
/**
* Add `id`s to headings.
*
* @param {Options | null | undefined} [options]
* Configuration (optional).
* @returns
* Transform.
*/
export default function rehypeSlug(options) {
const settings = options || emptyOptions
const prefix = settings.prefix || ''
/**
* @param {Root} tree
* Tree.
* @returns {undefined}
* Nothing.
*/
return function (tree) {
slugs.reset()
visit(tree, 'element', function (node) {
if (headingRank(node) && !node.properties.id) {
node.properties.id = prefix + slugs.slug(toString(node))
}
})
}
}import GithubSlugger from 'github-slugger'
import {headingRank} from 'hast-util-heading-rank'
import {toString} from 'hast-util-to-string'
import {visit} from 'unist-util-visit'
/** @type {Options} */
const emptyOptions = {}
const slugs = new GithubSlugger()
/**
* Add `id`s to headings.
*
* @param {Options | null | undefined} [options]
* Configuration (optional).
* @returns
* Transform.
*/
export default function rehypeSlug(options) {
const settings = options || emptyOptions
const prefix = settings.prefix || ''
/**
* @param {Root} tree
* Tree.
* @returns {undefined}
* Nothing.
*/
return function (tree) {
slugs.reset()
visit(tree, 'element', function (node) {
if (headingRank(node) && !node.properties.id) {
node.properties.id = prefix + slugs.slug(toString(node))
}
})
}
}살펴보니 내부적으로 github-slugger를 사용하는걸 확인할 수 있습니다.
GithubSlugger 인스턴스를 만들어서 별다른 옵션이 없을 경우 node 의 id 속성에 slug를 생성해서 넣어주고 있습니다.
TOC를 만들때 github-slugger를 이용하여 id값을 생성하면 될 거 같습니다.
3. 본문글에서 TOC를 위한 데이터를 추출하기
전체적인 TOC추출 코드의 모습입니다.
export const parseHeadersForTOC = (raw: string) => {
const calculateHeaderLevels = (arr: Array<number>) => {
const sorted = [...arr].sort((a, b) => a - b);
const min = sorted[0];
const adjusted = arr.map((value) => value - min + 1);
return adjusted;
};
const regex = /\n(?<flag>#{1,3})\s+(?<text>.+)/g;
const headerMatches = Array.from(raw.matchAll(regex));
const headerLevels = calculateHeaderLevels(
headerMatches.map((match) => match.groups?.flag.length!),
) as Array<1 | 2 | 3>;
const slugger = new GithubSlugger();
const headers: Toc[] = headerMatches.map((header, i) => {
const { text } = header.groups || { text: '' };
const slug = slugger.slug(text);
return { level: headerLevels[i], text, slug };
});
return headers;
};
export const parseHeadersForTOC = (raw: string) => {
const calculateHeaderLevels = (arr: Array<number>) => {
const sorted = [...arr].sort((a, b) => a - b);
const min = sorted[0];
const adjusted = arr.map((value) => value - min + 1);
return adjusted;
};
const regex = /\n(?<flag>#{1,3})\s+(?<text>.+)/g;
const headerMatches = Array.from(raw.matchAll(regex));
const headerLevels = calculateHeaderLevels(
headerMatches.map((match) => match.groups?.flag.length!),
) as Array<1 | 2 | 3>;
const slugger = new GithubSlugger();
const headers: Toc[] = headerMatches.map((header, i) => {
const { text } = header.groups || { text: '' };
const slug = slugger.slug(text);
return { level: headerLevels[i], text, slug };
});
return headers;
};raw파라미터에는 아래 형식과 같은 문자열이 들어오게 됩니다.
# toc
toc level1 입니다.
## toc
toc level2 입니다.
### toc
toc level3 입니다.# toc
toc level1 입니다.
## toc
toc level2 입니다.
### toc
toc level3 입니다."#" 의 개수 n에 따라 heading의 뎁스가 결정이 됩니다.
정규식(/\n(?<flag>#{1,3})\s+(?<text>.+)/g)을 통해서 제목 태그의 level과 제목 태그의 텍스트를 그룹핑합니다.
각 제목 태그가 개행 문자로 시작하므로
\n을 넣어줍니다.
(?<flag>#{1,3})는 flag라는 이름의 그룹을 정의합니다. 이 그룹은 # 문자 1개에서 3개까지 연속으로 나타나는 것을 의미합니다. 즉, #, ##, 또는 ###와 일치하는 것을 찾습니다.
\s+는 하나 이상의 공백 문자를 나타냅니다. 이 공백은 #과 제목 텍스트를 구분합니다.
(?<text>.+)는 text라는 이름의 그룹을 정의합니다. 이 그룹은 하나 이상의 문자(.+)를 의미하며, 제목의 실제 텍스트를 찾습니다.
/g는 전역 검색을 활성화하는 플래그로, 문자열 내에서 모든 일치 항목을 찾아야 함을 나타냅니다.
matchAll을 통해 일치하는 패턴들을 다 찾아주고 배열로 만들어 줍니다.
const headerMatches = Array.from(raw.matchAll(regex));
console.log('headerMatches', headerMatches);
// headerMatches [
// [
// '\n# toc',
// '#',
// 'toc',
// index: 0,
// input: '\n# toc\ntoc level1 입니다.\n## toc\ntoc level2 입니다.\n### toc\ntoc level3 입니다.\n\n',
// groups: [Object: null prototype] { flag: '#', text: 'toc' }
// ],
// [
// '\n## toc',
// '##',
// 'toc',
// index: 22,
// input: '\n# toc\ntoc level1 입니다.\n## toc\ntoc level2 입니다.\n### toc\ntoc level3 입니다.\n\n',
// groups: [Object: null prototype] { flag: '##', text: 'toc' }
// ],
// [
// '\n### toc',
// '###',
// 'toc',
// index: 45,
// input: '\n# toc\ntoc level1 입니다.\n## toc\ntoc level2 입니다.\n### toc\ntoc level3 입니다.\n\n',
// groups: [Object: null prototype] { flag: '###', text: 'toc' }
// ]
// ]const headerMatches = Array.from(raw.matchAll(regex));
console.log('headerMatches', headerMatches);
// headerMatches [
// [
// '\n# toc',
// '#',
// 'toc',
// index: 0,
// input: '\n# toc\ntoc level1 입니다.\n## toc\ntoc level2 입니다.\n### toc\ntoc level3 입니다.\n\n',
// groups: [Object: null prototype] { flag: '#', text: 'toc' }
// ],
// [
// '\n## toc',
// '##',
// 'toc',
// index: 22,
// input: '\n# toc\ntoc level1 입니다.\n## toc\ntoc level2 입니다.\n### toc\ntoc level3 입니다.\n\n',
// groups: [Object: null prototype] { flag: '##', text: 'toc' }
// ],
// [
// '\n### toc',
// '###',
// 'toc',
// index: 45,
// input: '\n# toc\ntoc level1 입니다.\n## toc\ntoc level2 입니다.\n### toc\ntoc level3 입니다.\n\n',
// groups: [Object: null prototype] { flag: '###', text: 'toc' }
// ]
// ]calculateHeaderLevels 함수는 제목 태그의 수준을 계산합니다.
입력으로 level이 담긴 배열을 받아 해당 배열의 각 요소 간의 차이를 계산하여 최소 level을 1로 조정한 배열을 반환합니다.(예를들어 제목태그에 heading2 밖에 존재하지 않을 경우 level이 1로 계산이 되고, heading1과 headgin2가 존재할 경우 heading1의 level이 1로 계산이 됩니다.)
const headerLevels = calculateHeaderLevels(
headerMatches.map((match) => match.groups?.flag.length!),
) as Array<1 | 2 | 3>;const headerLevels = calculateHeaderLevels(
headerMatches.map((match) => match.groups?.flag.length!),
) as Array<1 | 2 | 3>;headerMathces 배열을 map함수를 이용하여 level,text,slug 속성을 가진 배열을 반환해줍니다. slug는 아까 위에서 받은 GithubSlugger 를 통해서 생성을 해주면 됩니다.
const slugger = new GithubSlugger();
const headers: Toc[] = headerMatches.map((header, i) => {
const { text } = header.groups || { text: '' };
const slug = slugger.slug(text);
return { level: headerLevels[i], text, slug };
});
return headers;
const slugger = new GithubSlugger();
const headers: Toc[] = headerMatches.map((header, i) => {
const { text } = header.groups || { text: '' };
const slug = slugger.slug(text);
return { level: headerLevels[i], text, slug };
});
return headers;
parseHeadersForTOC 함수의 최종 결과입니다.
[
{ level: 1, text: 'toc', slug: 'toc' },
{ level: 2, text: 'toc', slug: 'toc-1' },
{ level: 3, text: 'toc', slug: 'toc-2' }
]
4. 제목 태그 감지하기
글을 스크롤하며 읽을 때 제목 태그를 자동 감지하여 TOC를 자동으로 활성화하는 기능을 구현해야 합니다.
위 기능을 구현하는 방법은 두가지 정도가 있습니다.
- intersection observer를 이용하여 제목 태그가 감지되면 TOC활성화
- scroll event를 이용하여 특정 높이에 위치하면 TOC활성화
저는 1번 방법으로 구현을 했다가 2번 방법으로 변경했습니다.
1번 방법은 고속 스크롤 상황에서 요소를 제대로 감지하지 못하는 이슈가 있었습니다.
그래서 생각이 난 방법은 scroll event로 처리를 하는 방법이였습니다.
velog의 toc는 감지가 잘 된다고 느껴서 코드를 참고 해보니 scroll event를 사용하고 있었습니다.
intersection observer, scroll event를 이용한 코드를 각각 살펴보겠습니다. (스타일링 코드는 제외 했습니다.)
intersection observer로 구현
intersection observer를 이용했을 때 느낀 최대 장점은 코드가 간결해서 이해하기가 쉽다는 점이였습니다.
또한, 요소의 상태 변경을 관찰할 때 비동기 콜백으로 동작하기 때문에 scroll event보다 성능상의 이점도 챙길 수 있습니다.
단점은 고속 스크롤 상황에서 intersection observer가 제대로 동작하지 않아서 TOC하이라이팅이 제대로 되지 않는 이슈 입니다.
아래 코드는 블로그 글 안의 h1,h2,h3태그를 다 가져와서 관찰할 요소로 지정을 해주고 감지가 될 경우 해당 요소의 id를 activeToc 에 세팅을 해줍니다.
activeToc 와 일치하는 toc의 slug에 스타일링을 해주면 끝입니다. (뎁스에 따른 스타일 처리는 여기서
구현하지 않겠습니다.)
import { type Toc } from '@/lib/types/toc-type';
import Link from 'next/link';
import { useEffect, useRef, useState } from 'react';
interface TocSideProps {
tableOfContents: Toc[];
}
const TocSide = ({ tableOfContents }: TocSideProps) => {
const observer = useRef<IntersectionObserver>();
const [activeToc, setActiveToc] = useState('');
useEffect(() => {
observer.current = new IntersectionObserver(
(entries) => {
entries.forEach((entry) => {
if (!entry.isIntersecting) return;
setActiveToc(entry.target.id);
});
},
{
rootMargin: '0px 0px -95% 0px',
threshold: 1.0,
},
);
const headingElements = document.querySelectorAll('.prose h1,h2,h3');
headingElements.forEach((element) => observer.current?.observe(element));
return () => observer.current?.disconnect();
}, []);
return (
<>
{tableOfContents.length ? (
<ul>
<div>
목차
</div>
{tableOfContents.map((toc, i) => (
<li
data-level={numberToStringMap[toc.level]}
key={i}
className={`${activeToc === toc.slug ? 'active' : ''}`}
>
<Link href={`#${toc.slug}`}>{toc.text}</Link>
</li>
))}
</ul>
) : null}
</>
);
};
export default TocSide;import { type Toc } from '@/lib/types/toc-type';
import Link from 'next/link';
import { useEffect, useRef, useState } from 'react';
interface TocSideProps {
tableOfContents: Toc[];
}
const TocSide = ({ tableOfContents }: TocSideProps) => {
const observer = useRef<IntersectionObserver>();
const [activeToc, setActiveToc] = useState('');
useEffect(() => {
observer.current = new IntersectionObserver(
(entries) => {
entries.forEach((entry) => {
if (!entry.isIntersecting) return;
setActiveToc(entry.target.id);
});
},
{
rootMargin: '0px 0px -95% 0px',
threshold: 1.0,
},
);
const headingElements = document.querySelectorAll('.prose h1,h2,h3');
headingElements.forEach((element) => observer.current?.observe(element));
return () => observer.current?.disconnect();
}, []);
return (
<>
{tableOfContents.length ? (
<ul>
<div>
목차
</div>
{tableOfContents.map((toc, i) => (
<li
data-level={numberToStringMap[toc.level]}
key={i}
className={`${activeToc === toc.slug ? 'active' : ''}`}
>
<Link href={`#${toc.slug}`}>{toc.text}</Link>
</li>
))}
</ul>
) : null}
</>
);
};
export default TocSide;scroll event로 구현
intersection observer에 비해 코드가 간결하지 않습니다.
하지만, 동작은 intersection observer에 비해 정교해졌습니다.
tableOfContents를 map함수를 이용하여 doucment 에서 각 slug별로 해당하는 heading id를 찾고 찾은 요소는 현재 viewport에서 얼마나 떨어져 있는지(el.getBoundingClientRect().top)와 현재 document가 스크롤된 위치(scrollTop)을 더해줍니다. (el.getBoundingClientRect().top은 요소와 viewport사이의 상대적인 값을 가져오므로 만약 document를 100만큼 스크롤을 했으면 값이 -100이 되기 때문에 scrollTop은 꼭 더해줘야 합니다.)
블로그 게시글의 제목 태그가 어느정도로 스크롤 했을때 어떤 TOC요소와 매칭되는지에 대한 값을 구했으므로 scroll event를 통해 비교를 해주면서 하이라이팅 처리를 해줍니다.
그리고 trackScrollHeight 라는 메서드를 이용해서 0.25초 마다 주기적으로 이전 scrollHeight와 현재 scrollHeight가 같지 않을 경우 settingHeadingTops을 호출해주면서 제목 태그의 top 값을 재조정 해줍니다. (화면의 높이가 변경된 경우 재조정을 해주기 위함)
intersection observer와 마찬가지로 이제 activeToc 와 일치하는 toc의 slug에 스타일링을 해주면 끝입니다.
import { type Toc } from '@/lib/types/toc-type';
import Link from 'next/link';
import { useCallback, useEffect, useState } from 'react';
const numberToStringMap = {
1: 'one',
2: 'two',
3: 'three',
};
const getScrollTop = () => {
if (!document.body) return 0;
if (document.documentElement && 'scrollTop' in document.documentElement) {
return document.documentElement.scrollTop || document.body.scrollTop;
} else {
return document.body.scrollTop;
}
};
interface IHeadingTops {
slug: string;
top: number;
}
interface TocSideProps {
tableOfContents: Toc[];
}
const TocSide = ({ tableOfContents }: TocSideProps) => {
const [activeToc, setActiveToc] = useState('');
const [headingTops, setHeadingTops] = useState<null | IHeadingTops[]>([]);
const settingHeadingTops = useCallback(() => {
const scrollTop = getScrollTop();
const headingTops = tableOfContents.map(({ slug }) => {
const el = document.getElementById(slug);
const top = el ? el.getBoundingClientRect().top + scrollTop : 0;
return { slug, top };
});
setHeadingTops(headingTops);
}, [tableOfContents]);
useEffect(() => {
settingHeadingTops();
let prevScrollHeight = document.body.scrollHeight;
let timeoutId: ReturnType<typeof setTimeout> | null = null;
const trackScrollHeight = () => {
const scrollHeight = document.body.scrollHeight;
if (prevScrollHeight !== scrollHeight) {
settingHeadingTops();
}
prevScrollHeight = scrollHeight;
timeoutId = setTimeout(trackScrollHeight, 250);
};
timeoutId = setTimeout(trackScrollHeight, 250);
return () => {
timeoutId && clearTimeout(timeoutId);
};
}, [settingHeadingTops]);
useEffect(() => {
const onScroll = () => {
const scrollTop = getScrollTop();
if (!headingTops) return;
const currentHeading = headingTops
.slice()
.reverse()
.find((headingTop) => scrollTop >= headingTop.top - 4);
if (currentHeading) {
setActiveToc(currentHeading.slug);
} else {
setActiveToc('');
}
};
onScroll();
window.addEventListener('scroll', onScroll);
return () => {
window.removeEventListener('scroll', onScroll);
};
}, [headingTops]);
return (
<>
{tableOfContents.length ? (
<ul>
<div>목차</div>
{tableOfContents.map((toc, i) => (
<li
data-level={numberToStringMap[toc.level]}
key={i}
className={`${activeToc === toc.slug ? 'active' : ''}`}
>
<Link href={`#${toc.slug}`}>{toc.text}</Link>
</li>
))}
</ul>
) : null}
</>
);
};
export default TocSide;import { type Toc } from '@/lib/types/toc-type';
import Link from 'next/link';
import { useCallback, useEffect, useState } from 'react';
const numberToStringMap = {
1: 'one',
2: 'two',
3: 'three',
};
const getScrollTop = () => {
if (!document.body) return 0;
if (document.documentElement && 'scrollTop' in document.documentElement) {
return document.documentElement.scrollTop || document.body.scrollTop;
} else {
return document.body.scrollTop;
}
};
interface IHeadingTops {
slug: string;
top: number;
}
interface TocSideProps {
tableOfContents: Toc[];
}
const TocSide = ({ tableOfContents }: TocSideProps) => {
const [activeToc, setActiveToc] = useState('');
const [headingTops, setHeadingTops] = useState<null | IHeadingTops[]>([]);
const settingHeadingTops = useCallback(() => {
const scrollTop = getScrollTop();
const headingTops = tableOfContents.map(({ slug }) => {
const el = document.getElementById(slug);
const top = el ? el.getBoundingClientRect().top + scrollTop : 0;
return { slug, top };
});
setHeadingTops(headingTops);
}, [tableOfContents]);
useEffect(() => {
settingHeadingTops();
let prevScrollHeight = document.body.scrollHeight;
let timeoutId: ReturnType<typeof setTimeout> | null = null;
const trackScrollHeight = () => {
const scrollHeight = document.body.scrollHeight;
if (prevScrollHeight !== scrollHeight) {
settingHeadingTops();
}
prevScrollHeight = scrollHeight;
timeoutId = setTimeout(trackScrollHeight, 250);
};
timeoutId = setTimeout(trackScrollHeight, 250);
return () => {
timeoutId && clearTimeout(timeoutId);
};
}, [settingHeadingTops]);
useEffect(() => {
const onScroll = () => {
const scrollTop = getScrollTop();
if (!headingTops) return;
const currentHeading = headingTops
.slice()
.reverse()
.find((headingTop) => scrollTop >= headingTop.top - 4);
if (currentHeading) {
setActiveToc(currentHeading.slug);
} else {
setActiveToc('');
}
};
onScroll();
window.addEventListener('scroll', onScroll);
return () => {
window.removeEventListener('scroll', onScroll);
};
}, [headingTops]);
return (
<>
{tableOfContents.length ? (
<ul>
<div>목차</div>
{tableOfContents.map((toc, i) => (
<li
data-level={numberToStringMap[toc.level]}
key={i}
className={`${activeToc === toc.slug ? 'active' : ''}`}
>
<Link href={`#${toc.slug}`}>{toc.text}</Link>
</li>
))}
</ul>
) : null}
</>
);
};
export default TocSide;마치며
성능상 이점을 챙기면서 빠르게 TOC를 구현하고 싶으면 intersection observer를 사용하고 시간을 더 들이더라도 ux에 신경을 쓸거면 scroll event를 사용하면 될 거 같습니다.
intersection observer를 이용하든 scroll event를 이용하든 뭐가 더 좋다고 단정은 지을수 없을거 같습니다.
상황에 맞는 기술을 적용하는게 좋은 개발자가 되는 길이라고 생각합니다.
읽어주셔서 감사합니다.
